
Upgrading PostgreSQL on AWS RDS with minimum or zero downtime
In this article I will share all the details regarding the upgrade of our databases on Amazon Cloud as well as unveil the reason why we ended up using Bucardofor asynchronous multi-master replication and why we have eventually upgraded our production database with downtime.
Contents
- Introduction
- Multi-master replication
- WTF is Bucardo
- Upgrading stage DB without downtime using Bucardo
- Production issues
- Upgrading production DB with downtime
- Key takeaways
Introduction
Our entire infrastructure is run by Amazon Cloud. We deploy our apps via ElasticBeanstalk and store our data in PostgreSQL RDS.
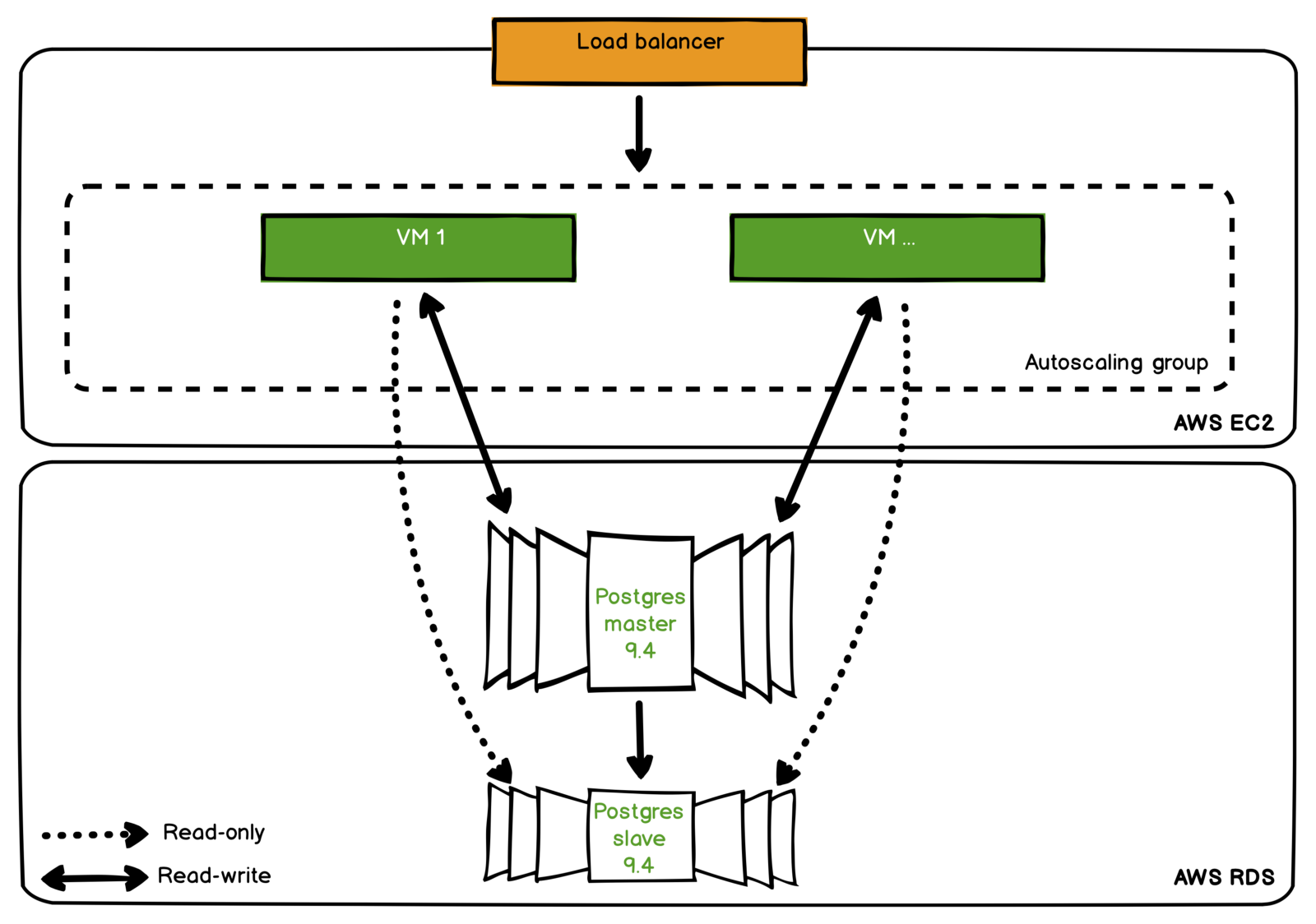
We use Amazon Redshift for storing analytics data (DWH). We needed to upgrade our stage and production PostgreSQL DB from 9.4 to 9.5 in order to make cross-platform queries between our PostgreSQL DB and Redshift with the help of dblink.
Amazon allows to bump only one major version of PostgreSQL. So you cannot simply upgrade it from 9.4 to 9.6 but only to 9.5 first and then repeat this procedure again from 9.5 to 9.6.
Also, you cannot get access to PostgreSQL superuser, because Amazon only allowsto create a user with RDS_SUPERUSER role with some limits.
You should have a login and password for RDS_SUPERUSER for allowing replica or use of non-default parameters group for changing some parameters. In case you lost or forgot your master password you could restore it without downtime. But if you want to change your parameters group — be ready to have a downtime.
Our main goal was to upgrade the database with zero downtime, and we could only achieve that by using multi-master replication of production database.
Multi-master replication
Unlike the well-known master-slave replication, multi-master means that your app has the ability to use same tables on different masters with all the changes being made automatically between all masters in this replication group.
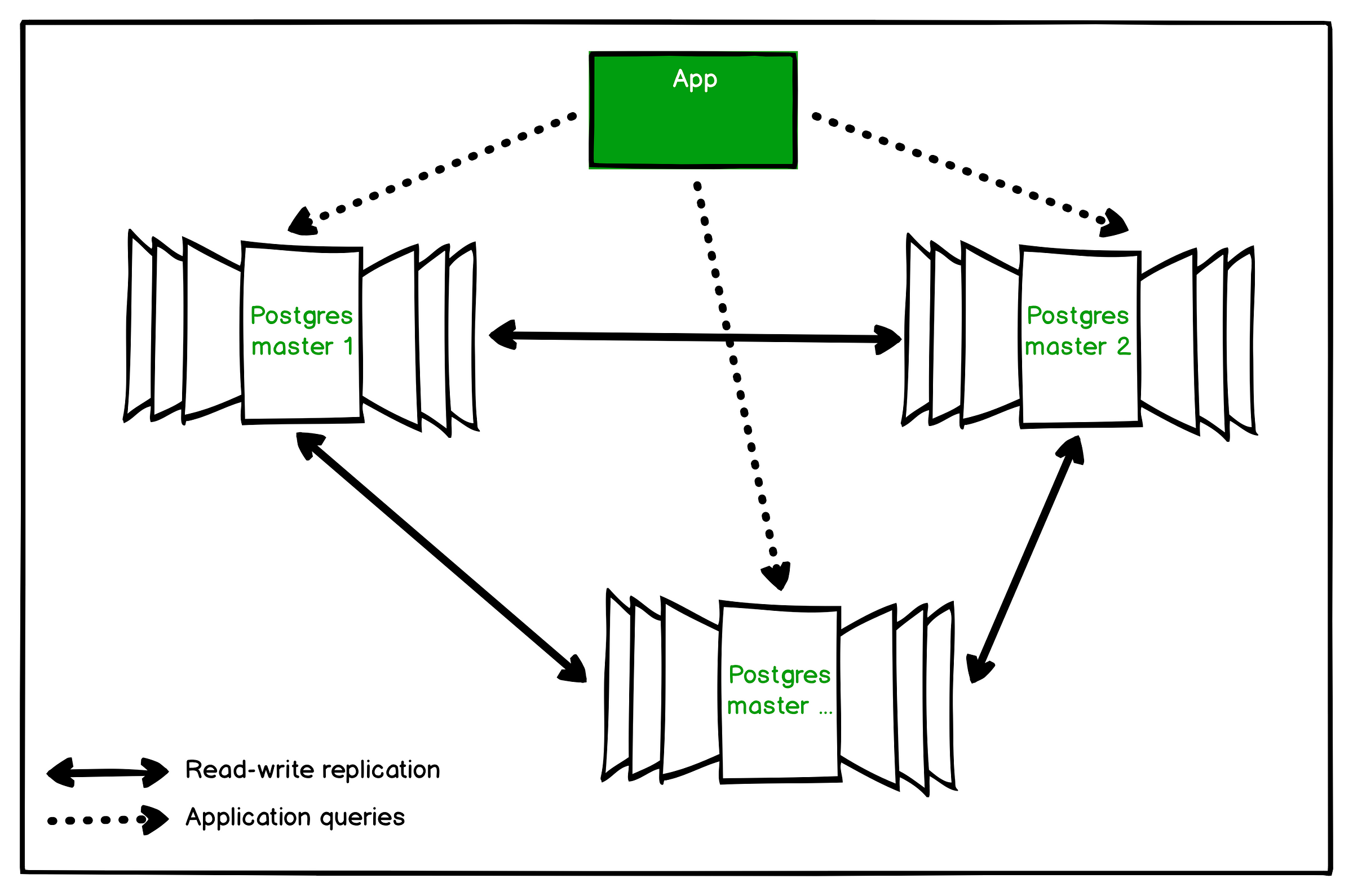
Setting up a reliable multi-master replication in PostgreSQL is undoubtedly challenging. Relational DBMSs aren’t designed for this purpose at all.
In case of a highload project, conflicts will inevitably occur and will have to be tracked and resolved somehow. In case they are launched automatically, conflict resolution systems can only overwrite data which will lead to their loss.
Frankly speaking, there are a lot of problems, and it’s better to use document-oriented DBMS with such tasks. But if you want to configure such replication for PostgreSQL, it’s desirable to have a database where:
- unlinked tables or limited presence of such links
- no foreign keys
- randomly not sequentially generated IDs
- preferably no triggers
Thankfully, we are not alone in this world and there are some tools that can help us solve these problems.
Here is a full list of them with a comparison matrix. After doing a bit of research, several instruments have been identified, among which:
- BDR
- PgCluster
- rubygrep
- Bucardo
Since our PostgreSQL server is not recompilable, it’s not really possible to use BDR and PgCluster because they require additional plugins. rubygrep, on the other hand, seems to be a dead project without any successful usage proof.
For the above stated reasons, Bucardoended up being the most attractive option and in the next paragraph I will illustrate why.
WTF is Bucardo
Bucardo is an asynchronous PostgreSQL replication system, that allows both multi-master and multi-slave operations. What is more important, Bucardo is a free open source software.
We chose Bucardo because of its stability, ease and good reviews. In fact, Bucardo is a perl-script which adds triggers to replicated tables for INSERT, UPDATE, DELETE operations and duplicate these operations to other servers through multi-master replication.
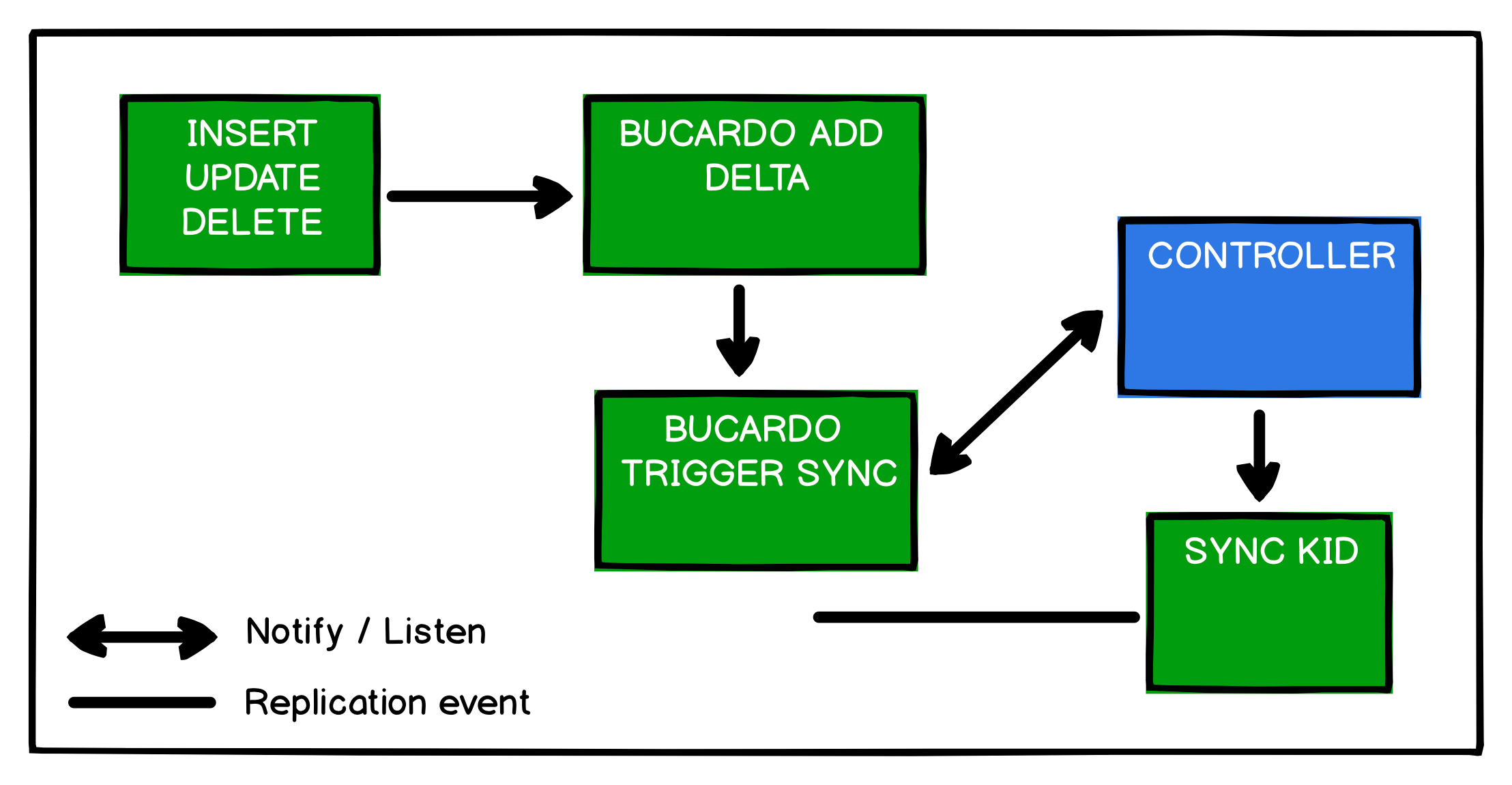
In order for Bucardo to work we should set:
- databases which participate in replication
- tables
- table and database groups
If a new table is added into one of masters in replica we should also add it to Bucardo manually, as it belongs to tables schemas.
Upgrading stage DB without downtime using Bucardo
So, we want to upgrade our PostgreSQL from 9.4 to 9.5 without downtime.
Here is a short playbook for it:
- take snapshot of existing RDS instance
- create new master based on this snapshot
- upgrade new master using AWS RDS
- create multi-master group, add both master servers to replica
- switch app from old master to new master
Let’s go!
Prerequisites
Get master’s endpoint and set credentials for DB:
export AWS_DEFAULT_REGION=eu-west-1 export MASTER_NAME=pgmaster export PGUSERNAME=rds_superuser export PGPASSWORD=rds_superuser_password
export PGENDPOINT=$(aws rds describe-db-instances --db-instance-identifier ${MASTER_NAME} --query 'DBInstances[*].Endpoint.[Address]' --output text)We need to have a superuser credentials for this DB. Remember it? We also recommend not to use default parameters group in RDS, create it before creating any new RDS instance.
Create a snapshot from DB instance:
aws rds create-db-snapshot \
--db-snapshot-identifier ${MASTER_NAME}-snapshot \
--db-instance-identifier ${MASTER_NAME}Wait for some time (depends on DB size) and check the snapshot status:
aws rds describe-db-snapshots --db-snapshot-identifier ${MASTER_NAME}-snapshot --query 'DBSnapshots[*].[Status]' --output text
availableCreate a new master, based on this snapshot:
aws rds restore-db-instance-from-db-snapshot \
--db-instance-identifier ${MASTER_NAME}-2 \
--db-snapshot-identifier ${MASTER_NAME}-snapshotWait for a couple of minutes and check new master status:
aws rds describe-db-instances --db-instance-identifier ${MASTER_NAME}-2 --query 'DBInstances[*].[DBInstanceStatus]' --output text
availablePGENDPOINT_2=$(aws rds describe-db-instances --db-instance-identifier ${MASTER_NAME}-2 --query 'DBInstances[*].Endpoint.[Address]' --output text)psql -h ${PGENDPOINT_2} -U ${PGUSERNAME} postgres -c "SHOW server_version;" -t 9.4.15At this time we have two instances: pgmaster and pgmaster-2. They are both PostgreSQL version 9.4 . Let’s upgrade our new master to 9.5 version.
Go to AWS Management Console and edit pgmaster-2 configuration:
- set same subnet group and security group as
pgmaster - set PostgreSQL version 9.5.13-R1
- set new parameters group (if you created it earlier)
Save configuration and apply changes immediately.
Wait for some minutes (or hours) and check new master’s version:
psql -h ${PGENDPOINT_2} -U ${PGUSERNAME} postgres -c "SHOW server_version;" -t 9.5.13Multi-master replication
For creating multi-master replication we need to have EC2 instance with Bucardo. Create new instance based on Ubuntu 16.04:
- use same region as RDS instances
- use same VPC, subnet group and security group as RDS
- tag:
Name — bucardo-stage - create new SSH keypair
bucardo-stage
Connect to instance and install Bucardo:
ssh ubuntu@bucardo-stage-ip -i bucardo-stage.pem apt update && apt install bucardo postgresql-plperl-9.5 -y export PGPASSWORD=yourSecurePasswordForPostgres
# Enable Bucardo and create workdir for it sed -i 's/ENABLED=0/ENABLED=1/' /etc/default/bucardo mkdir /var/run/bucardo # Setup superuser password for local DB sudo -u postgres psql postgres postgres=# \password postgres # Create DB and user for Bucardo psql -U postgres postgres << EOF CREATE USER bucardo WITH LOGIN SUPERUSER ENCRYPTED PASSWORD 'bucardoPassword'; CREATE DATABASE bucardo; EOF
bucardo install
Connect from bucardo-stage instance to RDS:
export PGENDPOINT=pgmaster.eu-west-1.rds.amazonaws.com export PGENDPOINT_2=pgmaster-2.eu-west-1.rds.amazonaws.com export PGUSERNAME=postgres export PGPASSWORD=yourSecurePasswordForPostgres
Prepare pgmaster and pgmaster-2servers for replication:
psql -h ${PGENDPOINT} -U ${PGUSERNAME} postgres -c "CREATE EXTENSION plperl;"
psql -h ${PGENDPOINT_2} -U ${PGUSERNAME} postgres -c "CREATE EXTENSION plperl;"Add servers to replication group:
export DATABASE=database
# Grant user postgres for tables and sequences
psql -h ${PGENDPOINT} -U ${PGUSERNAME} ${DATABASE} -W << EOF
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO postgres;
GRANT ALL PRIVILEGES ON ALL SEQUENCES IN SCHEMA public TO postgres;
EOFpsql -h ${PGENDPOINT_2} -U ${PGUSERNAME} ${DATABASE} -W << EOF
GRANT ALL PRIVILEGES ON ALL SEQUENCES IN SCHEMA public TO postgres;
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA public TO postgres;
EOF# Add both masters to Bucardo
bucardo add db source_db dbhost=${PGENDPOINT} dbport=5432 dbname=${DATABASE} dbuser=${PGUSERNAME} dbpass=${PGPASSWORD}
bucardo add db dest_db dbhost=${PGENDPOINT_2} dbport=5432 dbname=${DATABASE} dbuser=${PGUSERNAME} dbpass=${PGPASSWORD}
bucardo list databaseAdd all tables and sequences into the replication group:
bucardo add table all --db=source_db --herd=sample_herd bucardo add sequence all --db=source_db --herd=sample_herd
Create a multi-master replication group:
bucardo add dbgroup mydb_servers_group bucardo add dbgroup mydb_servers_group source_db:source bucardo add dbgroup mydb_servers_group dest_db:source bucardo add sync mydb_sync herd=sample_herd dbs=mydb_servers_group
bucardo list sync
We have two source databases here, it means that we have a multi-master replication, not a master-slave.
In a new terminal tab, run the script for checking DB downtime:
cat << EOF > checkdb.sh
#!/bin/bash
export PGPASSWORD=yourSecurePasswordForPostgres
export PGCONNECT_TIMEOUT=5
export DATABASE=database
export PGUSERNAME=postgres
while true; do
date
psql -h pgmaster-2.eu-west-1.rds.amazonaws.com \
-U ${PGUSERNAME} -d ${DATABASE} -t \
-c 'SELECT * FROM table LIMIT 1;'
sleep 2
done
EOF
bash checkdb.shThis script will be checking the connection to your new master with simple query every 2 seconds.
Start Bucardo:
bucardo start bucardo status
Replication testing
How it will be tested? We will run INSERT, UPDATE, DELETE operations on both masters and check how replica works.
INSERT
Write to source master, check on destination master:
psql -h ${PGENDPOINT} -U ${PGUSERNAME} ${DATABASE} \
-c "INSERT INTO table (id, name) VALUES (1, 'one');"
psql -h ${PGENDPOINT_2} -U ${PGUSERNAME} ${DATABASE} \
-c "SELECT * FROM table WHERE id=1;"Write to destination, check on source:
psql -h ${PGENDPOINT_2} -U ${PGUSERNAME} ${DATABASE} \
-c "INSERT INTO table (id, name) VALUES (2, 'two');"
psql -h ${PGENDPOINT} -U ${PGUSERNAME} ${DATABASE} \
-c "SELECT * FROM table WHERE id=2;"UPDATE
Update on source, check on destination:
psql -h ${PGENDPOINT} -U ${PGUSERNAME} ${DATABASE} -c "UPDATE table SET name='one_one' WHERE id=1;"psql -h ${PGENDPOINT_2} -p 5432 -U ${PGUSERNAME} ${DATABASE} -c "SELECT * FROM table WHERE id=1;"Update on destination, check on source:
psql -h ${PGENDPOINT_2} -U ${PGUSERNAME} ${DATABASE} -c "UPDATE table SET name='two_two' WHERE id=2;"psql -h ${PGENDPOINT} -U ${PGUSERNAME} ${DATABASE} -c "SELECT * FROM table WHERE id=2;"DELETE
Delete on source, check on destination:
psql -h ${PGENDPOINT} -U ${PGUSERNAME} ${DATABASE} -c "DELETE FROM table WHERE id=1;"psql -h ${PGENDPOINT_2} -U ${PGUSERNAME} ${DATABASE} -c "SELECT * FROM table WHERE id=1;"Delete on destination, check on source:
psql -h ${PGENDPOINT_2} -U ${PGUSERNAME} ${DATABASE} -c "DELETE FROM table WHERE id=2;"psql -h ${PGENDPOINT} -U ${PGUSERNAME} ${DATABASE} -c "SELECT * FROM table WHERE id=2;"Well, we tested our multi-master replication and it looks good.
Useful Bucardo commands
Let’s check Bucardo replication status:
bucardo delta source_db bucardo delta dest_db bucardo status mydb_sync
We also could check lag between masters using SQL:
psql -h ${PGENDPOINT} -p 5432 -U ${PGUSERNAME} ${DATABASE} \
-c "SELECT pg_last_xlog_receive_location() AS receive, pg_last_xlog_replay_location() AS replay , COALESCE(ROUND(EXTRACT(epoch FROM now() - pg_last_xact_replay_timestamp())),0) AS seconds;"App changes
Now we have a multi-master replication. The application is still using the old master for read-write operations, but we need to change application to a new master with new PostgreSQL version.
After that you can stop your replication:
bucardo validate all bucardo delta source_db bucardo delta dest_db bucardo deactivate mydb_sync bucardo remove sync mydb_sync bucardo stop
After stopping replica you can delete old RDS instance (we recommend you to create snapshot before doing so), create read-only replica for new master and delete Bucardo EC2 instance.
Don’t forget to revoke privileges for superuser and remove Bucardo’s tables:
psql -h ${PGENDPOINT_2} -U ${PGUSERNAME} ${DATABASE} << EOF
DROP SCHEMA bucardo CASCADE;
REVOKE ALL PRIVILEGES ON ALL TABLES IN SCHEMA public FROM postgres;
REVOKE ALL PRIVILEGES ON ALL SEQUENCES IN SCHEMA public FROM postgres;
EOFCool. Now we are ready to try it on prod!
Production issues
We tested this multi-master replication on test servers and stage and it works really good. But let’s not forget that in production we have significantly more requests.
When we have a lot of INSERT/UPDATE/DELETE operations with asynchronous streaming replication some lag may occur. If the app cannot control which master to use for write operations, we can get a primary keys collision. For example, when we are redeploying our app, some queries go to the old master and others to the new master.
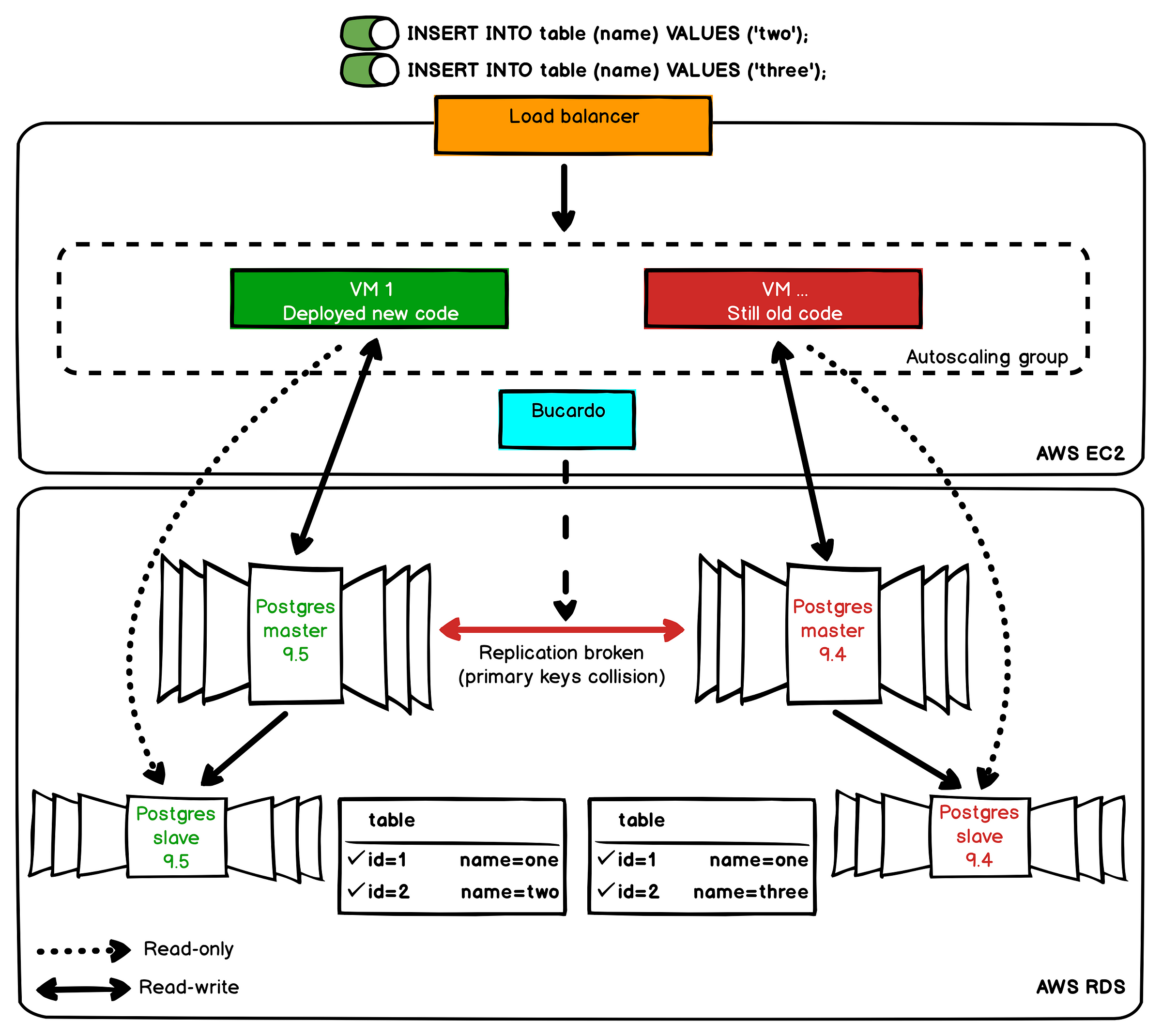
So, in our case we can’t use multi-master replication for production environment without changing app settings.
Upgrading production DB with downtime
First of all you should set a maintenance window.
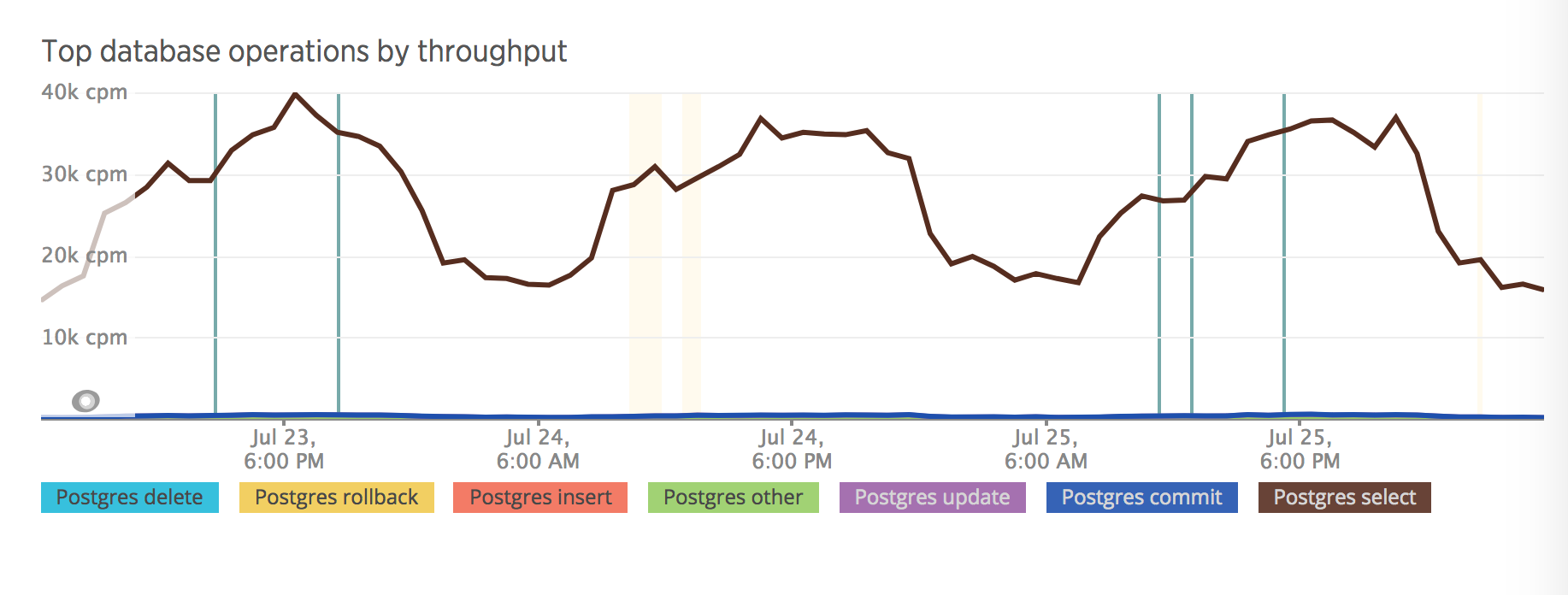
It’s easy when you have the DB metrics. In our example we have significantly fewer requests from 02:00 AM to 08:00 AM.
Also, it was crucial to understand which services cannot work during the DB downtime. We counted the downtime for RDS on test servers and it was only 4 min while it has reached 7 min on production server.
If you are all set and ready to rock and roll, here’s a production upgrade playbook for you to keep:
- make a first snapshot of production DB
- make second snapshot of production DB (it’s significantly faster than previous)
- run VACUUM operation before stopping instance
- modify DB version, instance type, parameters group and apply these changes immediately
- wait for upgrading DB
- delete old read-only replicas and create new ones
Key takeaways
RTFM: don’t use VACUUM FULL, instead of this use VACUUM command
VACUUM reclaims storage occupied by dead tuples without locking tables. VACUUM FULL rewrites all the table contents to a new disk file with no extra space, allowing unused space to be returned to the operating system. This form is much slower and requires an exclusive lock on each table while it is being processed. More information about it in PostgreSQL wiki.
Prepare you application for multi-master replication
If you want to use a multi-master replication in your project you need to make sure that the application will work with it correctly. Double check whether your application works with the DB and prepare the app for the multi-master.
Test everything
Run tests on all masters, check data consistency after tests, count possible downtime, etc.
Don’t forget about backups
Take snapshots as often as you can afford.
Communicate!
Gather all the information regarding the maintenance even if it doesn’t seem crucial. If you do a maintenance during off business hours, make sure that there are at least a few people with different domain knowledge, who can assist.
Have a detailed maintenance plan
Have a clear playbook for every maintenance: literally the set of commands, which you have to execute
Tag:aws, postgresql