
Postgres Database index Types
- Indexes are special lookup tables that the database search engine can use to speed up data retrieval. Simply put, an index is a pointer to data in a table. An index in a database is very similar to an index in the back of a book.
- For example, if you want to reference all pages in a book that discusses a certain topic, you have to first refer to the index, which lists all topics alphabetically and then refer to one or more specific page numbers.
- An index helps to speed up SELECT queries and WHERE clauses; however, it slows down data input, with UPDATE and INSERT statements. Indexes can be created or dropped with no effect on the data.
- Creating an index involves the CREATE INDEX statement, which allows you to name the index, to specify the table and which column or columns to index, and to indicate whether the index is in ascending or descending order.
- Indexes can also be unique, similar to the UNIQUE constraint, in that the index prevents duplicate entries in the column or combination of columns on which there’s an index.
The CREATE INDEX Command
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ [ IF NOT EXISTS ] name ] ON table_name [ USING method ]
( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ] [, ...] )
[ WITH ( storage_parameter = value [, ... ] ) ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ]
Index Types
PostgreSQL provides several index types:
- B-tree
- Hash
- Generalized Inverted Indexes (GIN)
- Generalized Search Tree (GiST)
- BRIN Indexes
Each Index type uses a different algorithm that is best suited to different types of queries.
Single-Column Indexes
CREATE INDEX index_name ON table_name (column_name);
multicolumn indexes(composite index):
CREATE INDEX index_name ON table_name (column1_name, column2_name);
create index ind on emp(emp_id, d_id);
Unique Indexes
Unique indexes are used not only for performance, but also for data integrity. A unique index does not allow any duplicate values to be inserted into the table. The basic syntax is as follows
create unique index ind1 on emp (empid,deptid);
An index is declared unique, multiple table rows with equal indexed values will not be allowed. Null values are not considered equal. A multicolumn unique index will only reject cases where all of the indexed columns are equal in two rows.
PostgreSQL automatically creates a unique index when a unique constraint or a primary key is defined for a table. The index covers the columns that make up the primary key or unique columns (a multicolumn index, if appropriate), and is the mechanism that enforces the constraint.
CREATE INDEX index_name on table_name (conditional_expression);
A partial index is an index built over a subset of a table; the subset is defined by a conditional expression (called the predicate of the partial index). The index contains entries only for those table rows that satisfy the predicate. The basic syntax is as follows −
CREATE INDEX index_name on table_name (conditional_expression);
For Example:
If you have a table that contains both billed and unbilled orders, where the unbilled orders take up a small fraction of the total table and yet those are the most-accessed rows, you can improve performance by creating an index on just the unbilled rows. The command to create the index would look like this:
CREATE INDEX orders_unbilled_index ON orders (order_nr)
WHERE billed is not true;
A possible query to use this index would be:
SELECT * FROM orders WHERE billed is not true AND order_nr < 10000;
However, the index can also be used in queries that do not involve order_nr at all, e.g.:
SELECT * FROM orders WHERE billed is not true AND amount > 5000.00;
This is not as efficient as a partial index on the amount column would be, since the system has to scan the entire index. Yet, if there are relatively few unbilled orders, using this partial index just to find the unbilled orders could be a win.
Note that this query cannot use this index:
SELECT * FROM orders WHERE order_nr = 3501;
The order 3501 might be among the billed or unbilled orders.
Implicit indexes are indexes that are automatically created by the database server when an object is created. Indexes are automatically created for primary key constraints and unique constraints.
collation for index uses
CREATE COLLATION defines a new collation using the specified operating system locale settings, or by copying an existing collation.
tutorialdba=> create collation fr_FR (locale = 'fr_FR.utf8'); CREATE COLLATION
tutorialdba=> create table test_d(french_name varchar2(10) collate "fr_FR",eng_name varchar2(10) collate "en_US"); CREATE TABLE
tutorialdba=> insert into test_d values('le','la');
INSERT 0 1
tutorialdba=> insert into test_d values('la','le');
INSERT 0 1
tutorialdba=> commit;
COMMIT
tutorialdba=> select * from test_d;
french_name | eng_name
-------------+----------
le | la
la | le
(2 rows)
tutorialdba=> \d test_d
Table "nijam.test_d"
Column | Type | Modifiers
-------------+-----------------------+---------------
french_name | character varying(10) | collate fr_FR
eng_name | character varying(10) | collate en_US
tutorialdba=> create index test_d_id1 on test_d(french_name collate "fr_FR");
CREATE INDEX
tutorialdba=> \d test_d
Table "nijam.test_d"
Column | Type | Modifiers
-------------+-----------------------+---------------
french_name | character varying(10) | collate fr_FR
eng_name | character varying(10) | collate en_US
Indexes:
"test_d_id1" btree (french_name)
tutorialdba=> create index test_d_id2 on test_d (eng_name collate "de_DE");
CREATE INDEX
tutorialdba=> \d test_d
Table "nijam.test_d"
Column | Type | Modifiers
-------------+-----------------------+---------------
french_name | character varying(10) | collate fr_FR
eng_name | character varying(10) | collate en_US
Indexes:
"test_d_id1" btree (french_name)
"test_d_id2" btree (eng_name COLLATE "de_DE")
tutorialdba=> create index t2_id1 on t2(sid) tablespace tbsone; CREATE INDEX tutorialdba=> select * from pg_indexes where tablename='t2'; schemaname | tablename | indexname | tablespace | indexdef ------------+-----------+-----------+------------+--------------------------------------------- nijam | t2 | t2_id1 | tbsone | CREATE INDEX t2_id1 ON t2 USING btree (sid) (1 row) tutorialdba=> select index_name,index_type, table_name, tablespace_name, status from user_indexes; index_name | index_type | table_name | tablespace_name | status --------------+------------+------------+-----------------+-------- T1_ID1 | BTREE | T1 | | VALID T1_LOWER_IDX | BTREE | T1 | | VALID T1_ID2 | BTREE | T1 | | VALID TEST_D_ID1 | BTREE | TEST_D | | VALID TEST_D_ID2 | BTREE | TEST_D | | VALID T2_ID1 | BTREE | T2 | TBSONE | VALID (6 rows)
Indexes on expressions:
tutorialdba=> create index on t1 (lower(name));
CREATE INDEX
tutorialdba=> \d t1;
Table "dinesh.t1"
Column | Type | Modifiers
--------+-----------------------+-----------
t_id | numeric(5,0) |
name | character varying(10) |
city | text |
Indexes:
"t1_id1" UNIQUE, btree (t_id)
"t1_lower_idx" btree (lower(name::text))
Tablespace: "tbsone"
To create a function based index:
tutorialdba=> create index t1_id2 on t1(upper(city));
CREATE INDEX
tutorialdba=> select * from t1 where upper(city)='CHENNAI';
tutorialdba=> \d t1;
Table "dinesh.t1"
Column | Type | Modifiers
--------+-----------------------+-----------
t_id | numeric(5,0) |
name | character varying(10) |
city | text |
Indexes:
"t1_id1" UNIQUE, btree (t_id)
"t1_id2" btree (upper(city))
"t1_lower_idx" btree (lower(name::text))
Tablespace: "tbsone"
create index ind on emp ((name||' '||fathersname)); select * from emp where ((name||' '||fathersname))='JACK McHALS';
EXAMINE INDEX USAGE
PostgreSQL do not need maintenance and tuning, it is still important to check which indexes are actually used by the real-life query workload. Examining index usage for an individual query is done with the EXPLAIN command;
tutorialdba=> explain analyze select * from land where id @>ARRAY[20];
QUERY PLAN
---------------------------------------------------------------------------
Seq Scan on land (cost=0.00..1.02 rows=1 width=33) (actual time=0.030..0.036 rows=2 loops=1)
Filter: (id @> '{20}'::integer[])
Total runtime: 0.089 ms
(3 rows)
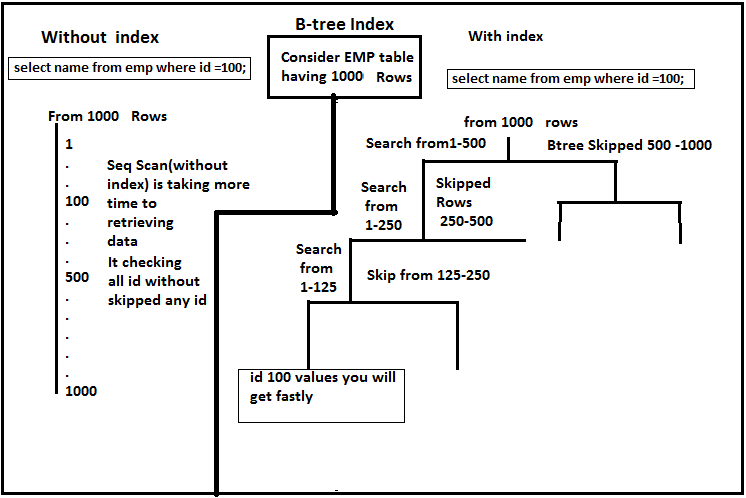
1. Btree Index:
By default, the CREATE INDEX command creates B-tree indexes, which fit the most common situations.
B-trees can handle equality and range queries on data that can be sorted into some ordering. In particular, the PostgreSQL query planner will consider using a B-tree index whenever an indexed column is involved in a comparison using one of these operators:
- <
- <=
- =
- >=
- >
Constructs equivalent to combinations of these operators, such as BETWEEN and IN, can also be implemented with a B-tree index search. (But note that IS NULL is not equivalent to = and is not indexable.)
The optimizer can also use a B-tree index for queries involving the pattern matching operators LIKE and ~ if the pattern is a constant and is anchored to the beginning of the string — for example, col LIKE ‘foo%’ or col ~ ‘^foo’, but not col LIKE ‘%bar’. However, if your server does not use the C locale you will need to create the index with a special operator class to support indexing of pattern-matching queries. See Section 11.8 below. It is also possible to use B-tree indexes for ILIKE and ~*, but only if the pattern starts with non-alphabetic characters, i.e. characters that are not affected by upper/lower case conversion.
When Should Indexes be Avoided?
- Indexes should not be used on small tables.
- Tables that have frequent, large batch update or insert operations.
- Indexes should not be used on columns that contain a high number of NULL values.
- Columns that are frequently manipulated should not be indexed.
\d emp # +-------------------------------------------------+ | Table "public.emp" | +-------------------------------------------------+ | Column | Type | Modifiers | +------------+------------------------+-----------+ | id | integer | not null | | first_name | character varying(60) | | | last_name | character varying(60) | | | email | character varying(120) | | | gender | character varying(6) | | | created_at | date | |
EXPLAIN SELECT * FROM emp where id=100;
QUERY PLAN
----------------------------------------------------------
Seq Scan on emp (cost=0.00..20.00 rows=1000 width=48)
(1 row)
CREATE INDEX email_idx ON emp USING btree(id);
\d emp # +-------------------------------------------------+ | Table "public.emp" | +-------------------------------------------------+ | Column | Type | Modifiers | +------------+------------------------+-----------+ | id | integer | not null | | first_name | character varying(60) | | | last_name | character varying(60) | | | email | character varying(120) | | | gender | character varying(6) | | | created_at | date | | +-------------------------------------------------+ |Indexes: | | "emp_pkey" PRIMARY KEY, btree (id) | +-------------------------------------------------+
EXPLAIN SELECT * FROM emp WHERE id = 100;
QUERY PLAN
----------------------------------------------------------------------
Index Scan using emp_pkey on emp (cost=0.28..11.28 rows=100 width=48)
Index Cond: (id = 100)
(2 rows)
See the cost with index and without index
if you use analyze you will get total runtime query runtime will be reduced atleast 2 to 3 times if you used index.
Explain analyze statement;
You can list down the entire indexes database wide using the \di command −
The DROP INDEX Command
DROP INDEX index_name;
DROP INDEX emp_pkey;
2. Hash Indexes:
Hash indexes can only handle simple equality comparisons. The query planner will consider using a hash index whenever an indexed column is involved in a comparison using the = operator. The following command is used to create a hash index:
create index ind_new on emp using hash(ename);
Testing has shown PostgreSQL’s hash indexes to perform no better than B-tree indexes, and the index size and build time for hash indexes is much worse. Furthermore, hash index operations are not presently WAL-logged, so hash indexes may need to be rebuilt with REINDEX after a database crash. For these reasons, hash index use is presently discouraged
tutorialdba=> create index s_idx on stud using hash(s_name);
CREATE INDEX
tutorialdba=> \d stud
Table "nijam.stud"
Column | Type | Modifiers
---------+-----------------------+-----------
s_id | numeric(8,0) |
s_name | character varying(10) |
s_dno | numeric(5,0) |
s_phone | numeric(10,0) |
Indexes:
"s_idx" hash (s_name)
3. Generalized Inverted Indexes (GIN)
GIN indexes are inverted indexes which can handle values that contain more than one key, arrays for example. Like GiST, GIN can support many different user-defined indexing strategies and the particular operators with which a GIN index can be used vary depending on the indexing strategy. As an example, the standard distribution of PostgreSQL includes GIN operator classes for one-dimensional arrays, which support indexed queries using these operators:
- <@
- @>
- =
- &&
Creates a GIN (Generalized Inverted Index)-based index. The column must be of tsvector type
GIN indexes accept a different parameter:
FASTUPDATE
This setting controls usage of the fast update technique described . It is a Boolean parameter: ON enables fast update, OFF disables it. (Alternative spellings of ON and OFF are allowed as described .) The default is ON.
tutorialdba=> create table land(id int[]);
CREATE TABLE
tutorialdba=> insert into "land" values ('{10, 20, 30}');
INSERT 0 1
tutorialdba=> insert into "land" values ('{20, 30, 40}');
INSERT 0 1
tutorialdba=> create index land_idx1 on land using gin("id");
CREATE INDEX
tutorialdba=> \d land
Table "dinesh.land"
Column | Type | Modifiers
--------+-----------+-----------
id | integer[] |
Indexes:
"land_idx1" gin (id)
tutorialdba=> select * from land;
id
------------
{10,20,30}
{20,30,40}
(2 rows)
tutorialdba=> analyze land; ANALYZE
tutorialdba=> explain analyze select * from land where id @>ARRAY[20];
QUERY PLAN
-----------------------------------------------------------------------------------------------
Seq Scan on land (cost=0.00..1.02 rows=1 width=33) (actual time=0.030..0.036 rows=2 loops=1)
Filter: (id @> '{20}'::integer[])
Total runtime: 0.089 ms
(3 rows)
4. Generalized Search Tree (GiST)
GiST indexes are not a single kind of index, but rather an infrastructure within which many different indexing strategies can be implemented. Accordingly, the particular operators with which a GiST index can be used vary depending on the indexing strategy (the operator class). As an example, the standard distribution of PostgreSQL includes GiST operator classes for several two-dimensional geometric data types, which support indexed queries using these operators:
- <<
- &<
- &>
- >>
- <<|
- &<|
- |&>
- |>>
- @>
- <@
- ~=
- &&
Many other GiST operator classes are available in the contrib collection or as separate projects.
tutorialdba=> create table text_g( id number(10),name varchar2(10),data circle); CREATE TABLE
tutorialdba=> create index gist_idx2 on text_g using gist(data); CREATE INDEX
tutorialdba=> \d text_g
Table "nijam.text_g"
Column | Type | Modifiers
--------+-----------------------+-----------
id | numeric(10,0) |
name | character varying(10) |
data | circle |
Indexes:
"gist_idx2" gist (data)
tutorialdba=> update text_g set data='10,4,10';
UPDATE 100
tutorialdba=> select count(*) from text_g
tutorialdba-> ;
count
-------
100
(1 row)
tutorialdba=> select * from text_g where id<10; id | name | data ----+------+------------- 1 | tutorialdba | <(10,4),10> 2 | tutorialdba | <(10,4),10> 3 | tutorialdba | <(10,4),10> 4 | tutorialdba | <(10,4),10> 5 | tutorialdba | <(10,4),10> 6 | tutorialdba | <(10,4),10> 7 | tutorialdba | <(10,4),10> 8 | tutorialdba | <(10,4),10> 9 | tutorialdba | <(10,4),10> (9 rows)
GiST Index-Only Scans
Previously, the only index access method that supported index-only scans was B-Tree and SP-GiST, but support is added for GiST in PostgreSQL 9.5:
In this example, we’ll be using the btree_gist extension:
# CREATE EXTENSION btree_gist;
We’ll set up a simple table that stores meeting room reservations:
# CREATE TABLE meetings ( id serial primary key, room int, reservation tstzrange);
Then we add an exclusion constraint to ensure that no booking for any one room overlaps another booking for the same room, which creates an index to enforce the constraint:
# ALTER TABLE meetings ADD CONSTRAINT meeting_exclusion EXCLUDE USING GIST (room with =, reservation with &&);
And we’ll populate it with lots of test data:
# WITH RECURSIVE ins AS (
SELECT
1 AS room,
'2000-01-01 08:00:00'::timestamptz AS reservation_start,
(ceil(random()*24)*5 || ' minutes')::interval as duration
UNION ALL
SELECT
CASE
WHEN ins.reservation_start > now() THEN ins.room + 1
ELSE ins.room
END AS room,
CASE
WHEN ins.reservation_start > now() THEN '2000-01-01 08:00:00'::timestamptz
ELSE ins.reservation_start + ins.duration
END AS reservation_start,
(ceil(random()*16)*15 || ' minutes')::interval AS duration
FROM ins
WHERE reservation_start < now() + '1 day'::interval
and room <= 200
)
INSERT INTO meetings (room, reservation)
SELECT room, tstzrange(reservation_start, reservation_start + duration) FROM ins
WHERE (reservation_start + duration)::time between '08:00' and '20:00';
One run of this results in 6.4 million rows.
If we get the query plan for counting how many meetings occurred during May in 2014 for each room:
# EXPLAIN SELECT room, count(*) FROM meetings WHERE reservation && '[2014-05-01,2014-05-31]'::tstzrange GROUP BY room ORDER BY room;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Sort (cost=1294.20..1294.21 rows=2 width=4)
Sort Key: room
-> HashAggregate (cost=1294.17..1294.19 rows=2 width=4)
Group Key: room
-> Index Only Scan using meeting_exclusion on meetings (cost=0.41..1113.98 rows=36038 width=4)
Index Cond: (reservation && '["2014-05-01 00:00:00+01","2014-05-31 00:00:00+01"]'::tstzrange)
Prior to 9.5, we would get the following plan:
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Sort (cost=28570.15..28570.16 rows=2 width=4)
Sort Key: room
-> HashAggregate (cost=28570.12..28570.14 rows=2 width=4)
Group Key: room
-> Bitmap Heap Scan on meetings (cost=778.49..28386.07 rows=36810 width=4)
Recheck Cond: (reservation && '["2014-05-01 00:00:00+01","2014-05-31 00:00:00+01"]'::tstzrange)
-> Bitmap Index Scan on meeting_exclusion (cost=0.00..769.29 rows=36810 width=0)
Index Cond: (reservation && '["2014-05-01 00:00:00+01","2014-05-31 00:00:00+01"]'::tstzrange)
Difference between GIN and GIST index in postgreSQL :
- GIN index lookups are about three times faster than GiST(select)
- GIN indexes take about three times longer to build than GiST
- GIN indexes are moderately slower to update than GiST indexes, but about 10 times slower if fast-update support was disabled (update)
- GIN indexes are two-to-three times larger than GiST indexes (space)
5. BRIN Indexes
BRIN stands for Block Range INdexes, and store metadata on a range of pages. At the moment this means the minimum and maximum values per block.
This results in an inexpensive index that occupies a very small amount of space, and can speed up queries in extremely large tables. This allows the index to determine which blocks are the only ones worth checking, and all others can be skipped. So if a 10GB table of order contained rows that were generally in order of order date, a BRIN index on the order_date column would allow the majority of the table to be skipped rather than performing a full sequential scan. This will still be slower than a regular BTREE index on the same column, but with the benefits of it being far smaller and requires less maintenance.
For example:
-- Create the table
CREATE TABLE orders (
id int,
order_date timestamptz,
item text);
-- Insert lots of data into it
INSERT INTO orders (order_date, item)
SELECT x, 'dfiojdso'
FROM generate_series('2000-01-01 00:00:00'::timestamptz, '2015-03-01 00:00:00'::timestamptz,'2 seconds'::interval) a(x);
-- Let's look at how much space the table occupies
# \dt+ orders
List of relations
Schema | Name | Type | Owner | Size | Description
--------+--------+-------+-------+-------+-------------
public | orders | table | thom | 13 GB |
(1 row)
-- What's involved in finding the orders between 2 dates
# EXPLAIN ANALYSE SELECT count(*) FROM orders WHERE order_date BETWEEN '2012-01-04 09:00:00' and '2014-01-04 14:30:00';
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=5425021.80..5425021.81 rows=1 width=0) (actual time=30172.428..30172.429 rows=1 loops=1)
-> Seq Scan on orders (cost=0.00..5347754.00 rows=30907121 width=0) (actual time=6050.015..28552.976 rows=31589101 loops=1)
Filter: ((order_date >= '2012-01-04 09:00:00+00'::timestamp with time zone) AND (order_date <= '2014-01-04 14:30:00+00'::timestamp with time zone))
Rows Removed by Filter: 207652500
Planning time: 0.140 ms
Execution time: 30172.482 ms
(6 rows)
-- Now let's create a BRIN index on the order_date column
CREATE INDEX idx_order_date_brin
ON orders
USING BRIN (order_date);
-- And see how much space it takes up
# \di+ idx_order_date_brin
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+---------------------+-------+-------+--------+--------+-------------
public | idx_order_date_brin | index | thom | orders | 504 kB |
(1 row)
-- Now let's see how much faster the query is with this very small index
# EXPLAIN ANALYSE SELECT count(*) FROM orders WHERE order_date BETWEEN '2012-01-04 09:00:00' and '2014-01-04 14:30:00';
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=2616868.60..2616868.61 rows=1 width=0) (actual time=6347.651..6347.651 rows=1 loops=1)
-> Bitmap Heap Scan on orders (cost=316863.99..2539600.80 rows=30907121 width=0) (actual time=36.366..4686.634 rows=31589101 loops=1)
Recheck Cond: ((order_date >= '2012-01-04 09:00:00+00'::timestamp with time zone) AND (order_date <= '2014-01-04 14:30:00+00'::timestamp with time zone))
Rows Removed by Index Recheck: 6419
Heap Blocks: lossy=232320
-> Bitmap Index Scan on idx_order_date_brin (cost=0.00..309137.21 rows=30907121 width=0) (actual time=35.567..35.567 rows=2323200 loops=1)
Index Cond: ((order_date >= '2012-01-04 09:00:00+00'::timestamp with time zone) AND (order_date <= '2014-01-04 14:30:00+00'::timestamp with time zone))
Planning time: 0.108 ms
Execution time: 6347.701 ms
(9 rows)
This example is on an SSD drive, so the results would be even more pronounced on an HDD.
By default, the block size is 128 pages. This resolution can be increased or decreased using the pages_per_range:
-- Create an index with 32 pages per block CREATE INDEX idx_order_date_brin_32 ON orders USING BRIN (order_date) WITH (pages_per_range = 32);
-- Create an index with 512 pages per block CREATE INDEX idx_order_date_brin_512 ON orders USING BRIN (order_date) WITH (pages_per_range = 512);
The lower the pages per block, the more space the index will occupy, but the less lossy the index will be, i.e. it will need to discard fewer rows.
# \di+ idx_order_date_brin*
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+-------------------------+-------+-------+--------+---------+-------------
public | idx_order_date_brin | index | thom | orders | 504 kB |
public | idx_order_date_brin_32 | index | thom | orders | 1872 kB |
public | idx_order_date_brin_512 | index | thom | orders | 152 kB |
(3 rows)
SET/RESET enable_seqscan;
PostgreSQL can use bitmap index scans to combine multiple indexes.
A predicate like
WHERE a > 50 AND a < 50000
is a specialisation of the more general form:
WHERE a > 50 and b < 50000 for a = b.
PostgreSQL can use two indexes here, one for each part of the predicate, and then bitmap AND them. It doesn’t matter if they happen to be on different ranges of the same column.
This is much less efficient than a single index, and may not be useful for some queries, but it’s possible.
The bigger problem is that PostgreSQL’s partial index support is not very bright. Irrespective of whether there’s one or two indexes it might just not figure out that it can use the index at all.
Demonstration setup:
CREATE TABLE partial (x integer, y integer); CREATE INDEX xs_above_50 ON partial(x) WHERE (x > 50); CREATE INDEX xs_below_50000 ON partial(x) WHERE (x < 5000); INSERT INTO partial(x,y) SELECT a, a FROM generate_series(1,100000) a;
OK, what will Pg prefer for given queries?
regress=> EXPLAIN SELECT y FROM partial WHERE x > 50 AND x < 50000;
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using xs_above_50 on partial (cost=0.29..1788.47 rows=50309 width=4)
Index Cond: ((x > 50) AND (x < 50000))
(2 rows)
regress=> EXPLAIN SELECT y FROM partial WHERE x > 20 AND x < 50000;
QUERY PLAN
--------------------------------------------------------------
Seq Scan on partial (cost=0.00..1943.00 rows=50339 width=4)
Filter: ((x > 20) AND (x < 50000))
(2 rows)
regress=> EXPLAIN SELECT y FROM partial WHERE x > 100 AND x < 50000;
QUERY PLAN
----------------------------------------------------------------------------------
Index Scan using xs_above_50 on partial (cost=0.29..1787.45 rows=50258 width=4)
Index Cond: ((x > 100) AND (x < 50000))
(2 rows)
regress=> EXPLAIN SELECT y FROM partial WHERE x > 100 AND x < 20000;
QUERY PLAN
---------------------------------------------------------------------------------
Index Scan using xs_above_50 on partial (cost=0.29..710.71 rows=19921 width=4)
Index Cond: ((x > 100) AND (x < 20000))
(2 rows)
What if we try to force a bitmap index scan just to find out if Pg can use one, even if it’s not worth doing for this particular simple case and small sample?
Try:
regress=> SET enable_seqscan = off;
SET
regress=> SET enable_indexscan = off;
SET
regress=> SET enable_indexonlyscan = off;
SET
regress=> EXPLAIN SELECT y FROM partial WHERE x > 100 AND x < 20000;
QUERY PLAN
--------------------------------------------------------------------------------
Bitmap Heap Scan on partial (cost=424.48..1166.30 rows=19921 width=4)
Recheck Cond: ((x > 100) AND (x < 20000))
-> Bitmap Index Scan on xs_above_50 (cost=0.00..419.50 rows=19921 width=0)
Index Cond: ((x > 100) AND (x < 20000))
(4 rows)
Hm. Nope. Not combining the indexes there. It might be able to but simply not think it’s worth scanning a second index, though.
What about a query that ORs two predicates instead?
regress=> EXPLAIN SELECT y FROM partial WHERE x > 100 OR x < 200;
QUERY PLAN
---------------------------------------------------------------------------------------
Bitmap Heap Scan on partial (cost=1905.29..3848.29 rows=99908 width=4)
Recheck Cond: ((x > 100) OR (x < 200))
-> BitmapOr (cost=1905.29..1905.29 rows=100000 width=0)
-> Bitmap Index Scan on xs_above_50 (cost=0.00..1849.60 rows=99908 width=0)
Index Cond: (x > 100)
-> Bitmap Index Scan on xs_below_50000 (cost=0.00..5.73 rows=193 width=0)
Index Cond: (x < 200)
(7 rows)
Here PostgreSQL has ORed both indexes to find a match, then done a heap scan and recheck.
So yes, PostgreSQL can combine multiple partial indexes, at least for some queries, where it is useful to do so.
But if I RESET the planner overrides…
regress=> RESET enable_seqscan;
RESET
regress=> RESET enable_indexscan ;
RESET
regress=> RESET enable_indexonlyscan ;
RESET
regress=> EXPLAIN SELECT y FROM partial WHERE x > 100 OR x < 200;
QUERY PLAN
--------------------------------------------------------------
Seq Scan on partial (cost=0.00..1943.00 rows=99908 width=4)
Filter: ((x > 100) OR (x < 200))
(2 rows)
How to Monitor with PostgreSQL Indexes
Tag:index Types, postgresql, reindex